Malware Coordination using the
Bitcoin Blockchain.
Whenever defenses become good enough to severely reduce their profits, malware authors deploy new techniques to circumvent the latest security mechanisms. Here, we report on the latest step in this cat-and-mouse game: The authors of the Cerber ransomware are now using the bitcoin blockchain to coordinate their infrastructure, which unfortunately means that many of the established network defenses against malware have become useless.
20 years of malware evolution
Whenever defenses become good enough to severely harm the operation of malware and reduce their profits, malware authors were fast to introduce innovations that would circumvent their efforts. Over the last 20 years, this has led to a cat and mouse game between adversaries and defenders.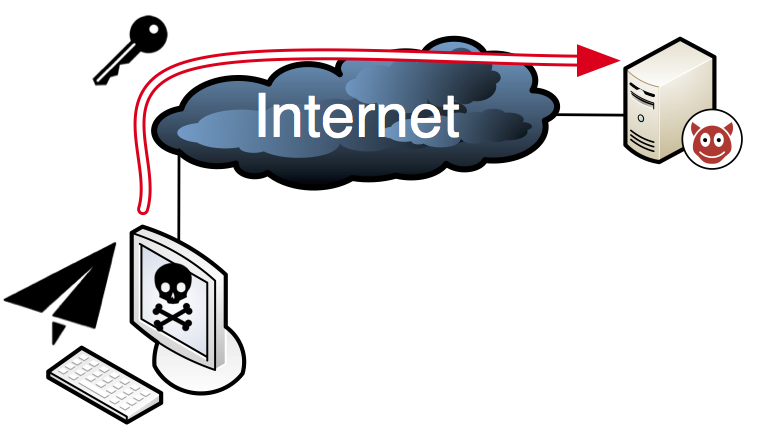
Suppose your PC has been infected by a ransomware that has encrypted on your hard drive and demands money to restore your data. What has happened in the background is that the malware has generated a random key with which it has done the encryption and uploaded this to the server of the cyber criminal. The interesting question is however how does the malware on your PC know where to send the key, and how can the criminal instruct the malware to release your files after payment?
Over the past 20 years, the way malware authors communicate with the infected clients has greatly changed. When the first generation of bot software came out in the late 90s, the infected clients connected via the Internet Relay Chat (IRC) protocol to their master. As there are many open IRC servers around the world to which anyone could connect, the malware authors could leverage this infrastructure for free, not have to worry about scalability, and realize control with minimal effort. As IRC is however seldom used by now, this communication readily stands out from "normal" network traffic and is easily blocked. In result, the perpetrators switched their systems to the HTTP protocol, which leds their bots traffic blend in with the myriads of web browsing and app requests all our devices continuously do.
These requests have to be somehow directed at the malware coordination server. While it would be easy to simply include the IP address of the server in the malware itself, an address can be trivially blocked by network administrators and the corresponding server identified and taken down. Malware thus connects via a domain name, whose destination can be dynamically updated, and over the years attackers have introduced techniques such as fluxing to make the tracking more difficult. Still, given some effort, also domain names can be taken out of service, usually in a coordinated effort between law enforcement and service providers. As these efforts take time, over the past years malware has reverted to the use of domain generation algorithms or DGAs. Instead of having one domain name, DGAs dynamically create a large number of candidate domain names per time intervals, sometimes thousands per day. When the infected host tries to contact the server, it runs the algorithm and tries to connect to each one until it has found the one in use. This creates interesting economics: the malware owner only needs to register one of these thousands of domain names to stay in contact with the bots, while the defender needs to block (or register) all of them to cut off access - which then only works until the next time interval.
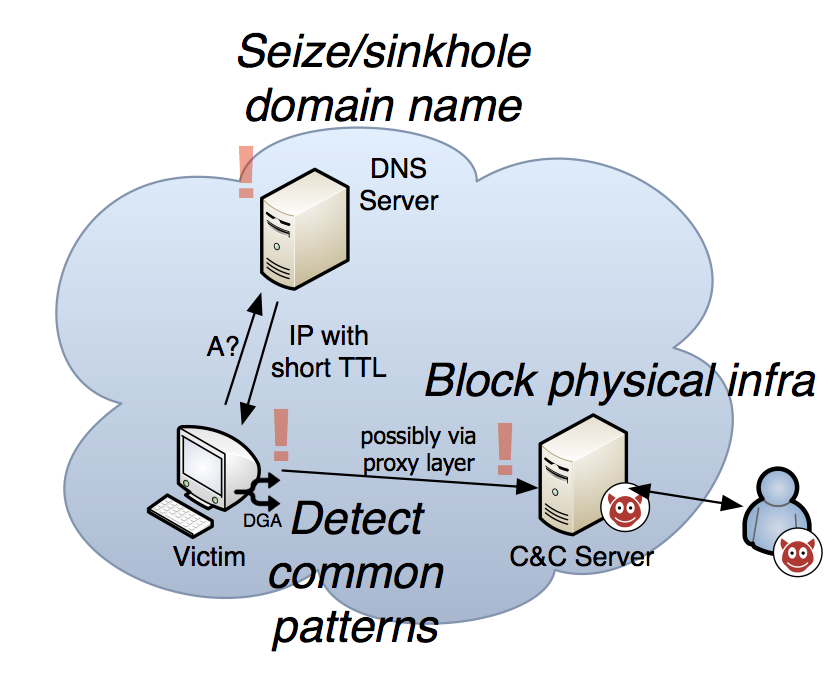
Three Network Detection Strategies
Given these design principles, network-based defense usually takes one of three angles:
- First, as an infected client would regenerate a lot of requests to non-existing domain names, so-called NXDomains, it is possible to pinpoint an infection in the local network. You may mistype domain name in your browser a few times a day, but doing hundreds of NXDomains is unlikely.
- Since the infected client needs to know the DGA, we can extract the algorithm from an infected machine, predict which domain names will be contacted and block these domain names for a short time.
- The domain names will point to the location of the coordination server, sometimes through additional deterrents such as proxy layers. If the location is known, the machine can be again taken offline.
Given these three techniques, an infection can be effectively controlled.
Storing the server addresses in the bitcoin blockchain
The authors of the Cerber ransomware introduced a new coordination principle that would render all three of these techniques ineffective. Cerber is an interesting ransomware for a variety of reasons: Checkpoint identified it as the most successful ransomware of 2016, with a market share of 25% and 150,000 infections in July 2016 alone. The ransomware has been estimated to provide $2.3 million in revenue per year, and it featured a new business model - ransomware-as-a-service - which was estimated to pay out $200,000 in commission per month.
Instead of computing the domain of the coordination server through a DGA (which would mean that a forensic analysis of the malware could extract and predict its future behavior), the ransomware authors stored the domain name in the bitcoin blockchain.
Infected clients would query the transactions of a particular bitcoin account using one of five benign payment websites. This would give the mechanism fault tolerance and not be easily blocked without creating collateral damage to users. These accounts exhibited an interesting transaction pattern: at apparently random time they send some money to another bitcoin address, only to get the exact some amount minus the transaction fee almost immediately sent back from them. These destination accounts were empty and before or after this exchange were never engaged in any other transaction.
To the infected clients, these transaction were however very insightful. The first 6 alphanumberic characters of the destination address would tell the infected PC where to find the server, as the malware owner had registered a matching domain name in the .top top-level zone, in the case of June 1 1fel3k.top. From the perspective of network-based migitation, this scheme creates some complications: First, as the client would learn the correct address from the bitcoin blockchain, it would never generate a lookup to a non-existing domain. Second, as the addresses of the domain names are random, it is impossible to predict the next value beforehand. Furthermore, the malware owner can instantaneously update the system whenever necessary. Note how sometimes new domains gets introduced within the same day, while others remain active for multiple days. Whenever the current domain is identified and universally blocked, one bitcoin transaction is enough to restore access.
As the domain name would still be pointing to a physical server, it would still be possible to locate and take down the coordination server. Cerber introduced another innovation: the server was hosted as a hidden service in the Tor overlay network (aka the "dark web"). As the average victim would likely not have installed a Tor browser to access a hidden service instance, the domain from the bitcoin blockchain pointed to a Tor2Web gateway which translated the requests from the client's web browser into a tunnel through the Tor network to the hidden service. This introduced an additional layer of security, as the host for which the location is known is actually expendible as it contains no keys or payment data which are all stored on the hidden service. If this host would be taken down, it can be trivially be replaced with a new one, while the real infrastructure managing the keys and payments continues uninterrupted.
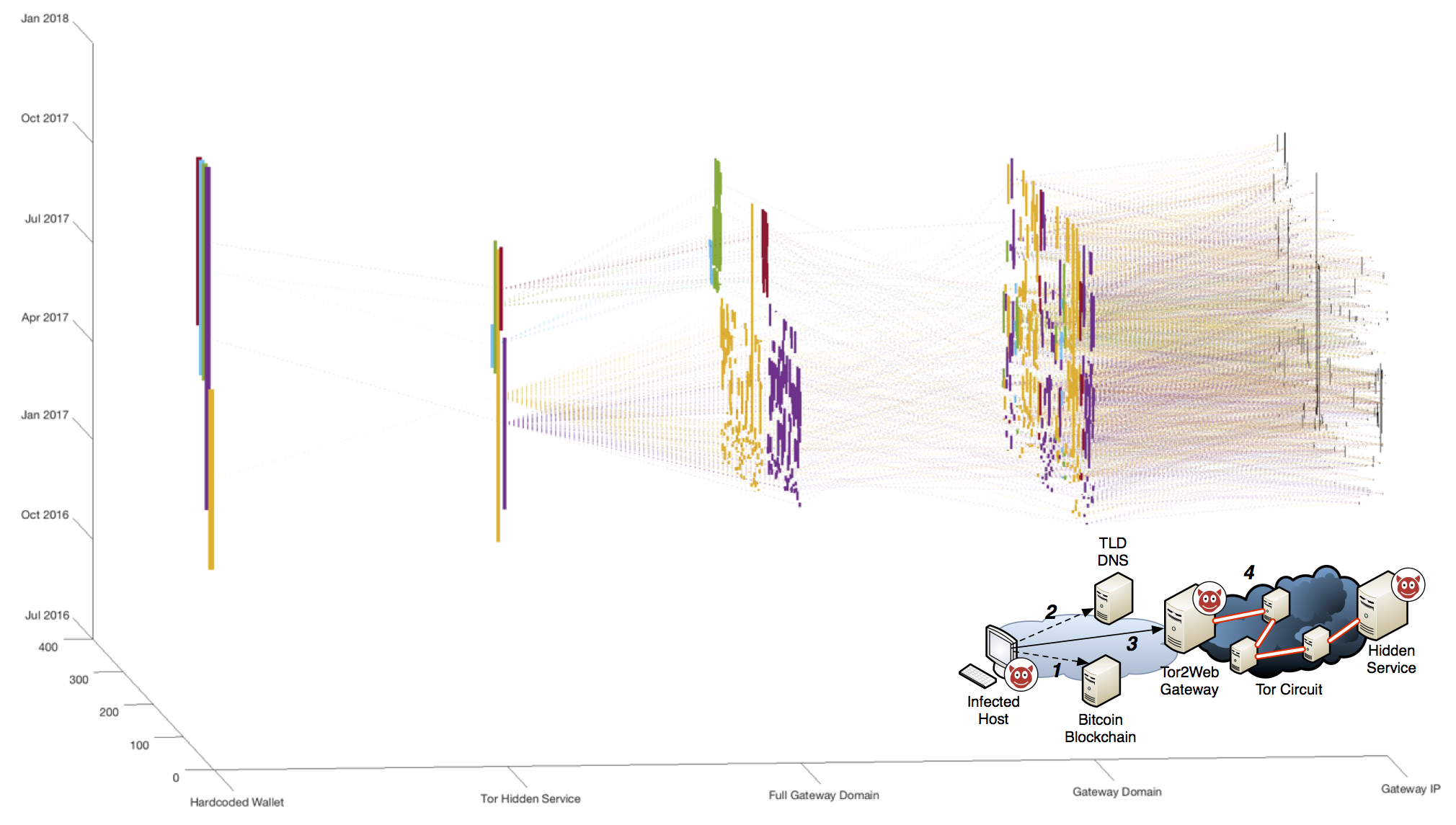
In this research project, we tracked the evolution of the Cerber ransomware campaigns for a period of 15 months. Collecting over 3700 indicators of compromise which are shown in relation above, we could observe how the perpetrators introduced the new mechanism, conducted field trials, ultimately rolled out the new coordination principle in production and then had to do refinements as the domain names and Tor2Web gateways were starting to be quickly blocked. This lead to unique insights into the operation of a criminal campaign. Some of the noteworth findings, which are described in detail in our paper:
- The perpetrators learned to identify networks which were either slow or inconsistent to respond to incidents. If a network is slow, it will mean that the Tor2Web gateway will be live longer and thereby reduce the effort to find a new hoster. If a network sometimes takes down instances immediately and sometimes only after long periods of time, this indicates a less mature incident response plan probably including significant manual work. We could show with very high statistical confidence (p < 0.001) that criminals identified and returned to host their infrastructure in networks that exhibited these properties.
- After the rollout in production, the domains and servers started to be rapidly blocked. We were able to show that this was due to how resources were placed. The others go through an experimentation and optimization phase, where the nearly all resources were swapped out (you can see the clear cut in the middle of the 3D figure where yellow and purple stops and is replced by red and green), before operation runs smoothly.
- The malware authors made operational mistakes which mean that all the campaigns could be linked together to the same group via commonly shared indicators. Asides from attribution, these mistakes made it also possible to explain the business model behind the "ransomware as a service". While it is possible that the Cerber developers sold licenses of their software to other criminals, the data shows the Cerber operated on a commission-based scheme, where infections all contacted a centrally managed infrastructure.
Although much was known about the Cerber ransomware in terms of the encryption used or its code base, this study offers new perspectives into the tactics, strategies and operational decisions from a threat intelligence perspective into one of the main ransomware campaigns to date.
Downloads
You can read more about this new coordination principle in our report:
S. Pletinckx, C. Trap and C. Doerr, Malware Coordination using the Blockchain: An Analysis of the Cerber Ransomware, IEEE Conference on Communications and Network Security 2018 [pdf]